Fran ois Marier: Things I do after uploading a new package to Debian
There are a couple of things I tend to do after packaging a piece of
software for Debian,
filing an Intent To Package bug and uploading
the package. This is both a checklist for me and (hopefully) a way to
inspire other maintainers to go beyond the basic package maintainer duties
as documented in the Debian Developer's
Reference.
If I've missed anything, please leave an comment or send me an email!
Salsa for collaborative development
To foster collaboration and allow others to contribute to the packaging, I
upload my package to a new subproject on
Salsa. By doing this, I enable other
Debian contributors to make improvements and propose changes via merge
requests.
I also like to upload the project logo in the settings page (i.e.
https://salsa.debian.org/debian/packagename/edit) since that will
show up on some dashboards like the Package
overview.
Salsa for collaborative development
To foster collaboration and allow others to contribute to the packaging, I
upload my package to a new subproject on
Salsa. By doing this, I enable other
Debian contributors to make improvements and propose changes via merge
requests.
I also like to upload the project logo in the settings page (i.e.
https://salsa.debian.org/debian/packagename/edit) since that will
show up on some dashboards like the Package
overview.
Launchpad for interacting with downstream Ubuntu users
While Debian is my primary focus, I also want to keep an eye on how my
package is doing on derivative distributions like Ubuntu.
To do this, I subscribe to bugs related to my
package
on Launchpad. Ubuntu bugs are rarely Ubuntu-specific and so I will often fix
them in Debian.
I also set myself as the answer contact on Launchpad
Answers
since these questions are often the sign of a Debian or a lack of
documentation.
I don't generally bother to fix bugs on Ubuntu directly though since
I've not had much luck with packages in universe lately. I'd rather not
spend much time preparing a package that's not going to end up being
released to users as part of a Stable Release
Update. On the other hand, I
have succesfully requested simple Debian
syncs when an important update
was uploaded after the Debian Import
Freeze.
Screenshots and tags
I take screenshots of my package and upload them on
https://screenshots.debian.net to help users understand what my package
offers and how it looks. I believe that these screenshots end up in software
"stores" type of applications.
Similarly, I add tags to my package using https://debtags.debian.org. I'm
not entirely sure where these tags are used, but they are visible from apt
show packagename.
Monitoring Upstream Releases
Staying up-to-date with upstream releases is one of the most important
duties of a software packager. There are a lot of different ways that upstream software
authors publicize their new releases. Here are some of the things I do to
monitor these releases:
- I have a cronjob which run
uscan once a day to check for new upstream
releases using the information specified in my debian/watch files:
0 12 * * 1-5 francois test -e /home/francois/devel/deb && HTTPS_PROXY= https_proxy= uscan --report /home/francois/devel/deb true
- I subscribe to the upstream project's releases RSS feed, if available. For
example, I subscribe to the GitHub tags feed for
git-secrets and
Launchpad announcements for
email-reminder.
- If the upstream project maintains an announcement mailing list, I
subscribe to it (e.g.
rkhunter-announce
or tor release announcements).
When nothing else is available, I write a cronjob that downloads the
upstream changelog once a day and commits it to a local git repo:
#!/bin/bash
pushd /home/francois/devel/zlib-changelog > /dev/null
wget --quiet -O ChangeLog.txt https://zlib.net/ChangeLog.txt exit 1
git diff
git commit -a -m "Updated changelog" > /dev/null
popd > /dev/null
This sends me a diff by email when a new release is added (and no emails otherwise).
universe lately. I'd rather not
spend much time preparing a package that's not going to end up being
released to users as part of a Stable Release
Update. On the other hand, I
have succesfully requested simple Debian
syncs when an important update
was uploaded after the Debian Import
Freeze.
Screenshots and tags
I take screenshots of my package and upload them on
https://screenshots.debian.net to help users understand what my package
offers and how it looks. I believe that these screenshots end up in software
"stores" type of applications.
Similarly, I add tags to my package using https://debtags.debian.org. I'm
not entirely sure where these tags are used, but they are visible from apt
show packagename.
Monitoring Upstream Releases
Staying up-to-date with upstream releases is one of the most important
duties of a software packager. There are a lot of different ways that upstream software
authors publicize their new releases. Here are some of the things I do to
monitor these releases:
- I have a cronjob which run
uscan once a day to check for new upstream
releases using the information specified in my debian/watch files:
0 12 * * 1-5 francois test -e /home/francois/devel/deb && HTTPS_PROXY= https_proxy= uscan --report /home/francois/devel/deb true
- I subscribe to the upstream project's releases RSS feed, if available. For
example, I subscribe to the GitHub tags feed for
git-secrets and
Launchpad announcements for
email-reminder.
- If the upstream project maintains an announcement mailing list, I
subscribe to it (e.g.
rkhunter-announce
or tor release announcements).
When nothing else is available, I write a cronjob that downloads the
upstream changelog once a day and commits it to a local git repo:
#!/bin/bash
pushd /home/francois/devel/zlib-changelog > /dev/null
wget --quiet -O ChangeLog.txt https://zlib.net/ChangeLog.txt exit 1
git diff
git commit -a -m "Updated changelog" > /dev/null
popd > /dev/null
This sends me a diff by email when a new release is added (and no emails otherwise).
- I have a cronjob which run
uscanonce a day to check for new upstream releases using the information specified in mydebian/watchfiles:0 12 * * 1-5 francois test -e /home/francois/devel/deb && HTTPS_PROXY= https_proxy= uscan --report /home/francois/devel/deb true - I subscribe to the upstream project's releases RSS feed, if available. For
example, I subscribe to the GitHub tags feed for
git-secretsand Launchpad announcements foremail-reminder. - If the upstream project maintains an announcement mailing list, I subscribe to it (e.g. rkhunter-announce or tor release announcements).
#!/bin/bash
pushd /home/francois/devel/zlib-changelog > /dev/null
wget --quiet -O ChangeLog.txt https://zlib.net/ChangeLog.txt exit 1
git diff
git commit -a -m "Updated changelog" > /dev/null
popd > /dev/null
 Man, you re no longer with us, but I am touched by the number of people you have positively impacted. Almost every DebConf23 presentations by locals I saw after you, carried how you were instrumental in bringing them there. How you were a dear friend and brother.
It s a weird turn of events, that you left us during one thing we deeply cared and worked towards making possible since the last 3 years together. Who would have known, that Sahil, I m going back to my apartment tonight and casual bye post that would be the last conversation we ever had.
Things were terrible after I heard the news. I had a hard time convincing myself to come see you one last time during your funeral. That was the last time I was going to get to see you, and I kept on looking at you. You, there in front of me, all calm, gave me peace. I ll carry that image all my life now. Your smile will always remain with me.
Now, who ll meet and receive me on the door at almost every Debian event (just by sheer co-incidence?). Who ll help me speak out loud about all the Debian shortcomings (and then discuss solutions, when sober :)).
Man, you re no longer with us, but I am touched by the number of people you have positively impacted. Almost every DebConf23 presentations by locals I saw after you, carried how you were instrumental in bringing them there. How you were a dear friend and brother.
It s a weird turn of events, that you left us during one thing we deeply cared and worked towards making possible since the last 3 years together. Who would have known, that Sahil, I m going back to my apartment tonight and casual bye post that would be the last conversation we ever had.
Things were terrible after I heard the news. I had a hard time convincing myself to come see you one last time during your funeral. That was the last time I was going to get to see you, and I kept on looking at you. You, there in front of me, all calm, gave me peace. I ll carry that image all my life now. Your smile will always remain with me.
Now, who ll meet and receive me on the door at almost every Debian event (just by sheer co-incidence?). Who ll help me speak out loud about all the Debian shortcomings (and then discuss solutions, when sober :)).
 It was a testament of the amount of time we had already spent together online, that when we first met during MDC Palakkad, it didn t feel we were physically meeting for the first time. The conversations just flowed.
Now
It was a testament of the amount of time we had already spent together online, that when we first met during MDC Palakkad, it didn t feel we were physically meeting for the first time. The conversations just flowed.
Now  Man, I still get your spelling wrong :) Did I ever tell you that? That was the reason, I used to use AR instead online.
You ll be missed and will always be part of our conversations, because you have left a profound impact on me, our friends, Debian India and everyone around. See you! the coolest man around.
In memory:
Man, I still get your spelling wrong :) Did I ever tell you that? That was the reason, I used to use AR instead online.
You ll be missed and will always be part of our conversations, because you have left a profound impact on me, our friends, Debian India and everyone around. See you! the coolest man around.
In memory:
 Suresh and me celebrating Onam in Kochi.
Suresh and me celebrating Onam in Kochi.
 Four Points Hotel by Sheraton was the venue of DebConf23. Photo credits: Bilal
Four Points Hotel by Sheraton was the venue of DebConf23. Photo credits: Bilal
 Photo of the pool. Photo credits: Andreas Tille.
Photo of the pool. Photo credits: Andreas Tille.
 View from the hotel window.
View from the hotel window.
 This place served as lunch and dinner place and later as hacklab during debconf. Photo credits: Bilal
This place served as lunch and dinner place and later as hacklab during debconf. Photo credits: Bilal
 Picture of the awesome swag bag given at DebConf23. Photo credits: Ravi Dwivedi
Picture of the awesome swag bag given at DebConf23. Photo credits: Ravi Dwivedi
 My presentation photo. Photo credits: Valessio
My presentation photo. Photo credits: Valessio
 Selfie with Anisa and Kristi. Photo credits: Anisa.
Selfie with Anisa and Kristi. Photo credits: Anisa.
 Me helping with the Cheese and Wine Party.
Me helping with the Cheese and Wine Party.
 This picture was taken when there were few people in my room for the party.
This picture was taken when there were few people in my room for the party.
 Sadhya Thali: A vegetarian meal served on banana leaf. Payasam and rasam were especially yummy! Photo credits: Ravi Dwivedi.
Sadhya Thali: A vegetarian meal served on banana leaf. Payasam and rasam were especially yummy! Photo credits: Ravi Dwivedi.
 Sadhya thali being served at debconf23. Photo credits: Bilal
Sadhya thali being served at debconf23. Photo credits: Bilal
 Group photo of our daytrip. Photo credits: Radhika Jhalani
Group photo of our daytrip. Photo credits: Radhika Jhalani
 A selfie in memory of Abraham.
A selfie in memory of Abraham.
 Thanks to Niibe Yutaka (the person towards your right hand) from Japan (FSIJ), who gave me a wonderful Japanese gift during debconf23: A folder to keep pages with ancient Japanese manga characters printed on it. I realized I immediately needed that :)
Thanks to Niibe Yutaka (the person towards your right hand) from Japan (FSIJ), who gave me a wonderful Japanese gift during debconf23: A folder to keep pages with ancient Japanese manga characters printed on it. I realized I immediately needed that :)
 This is the Japanese gift I received.
This is the Japanese gift I received.

 Bits from the DPL. Photo credits: Bilal
Bits from the DPL. Photo credits: Bilal
 Kristi on GNOME community. Photo credits: Ravi Dwivedi.
Kristi on GNOME community. Photo credits: Ravi Dwivedi.
 Abhas' talk on home automation. Photo credits: Ravi Dwivedi.
Abhas' talk on home automation. Photo credits: Ravi Dwivedi.
 I was roaming around with a QR code on my T-shirt for downloading Prav.
I was roaming around with a QR code on my T-shirt for downloading Prav.
 Me in mundu. Picture credits: Abhijith PA
Me in mundu. Picture credits: Abhijith PA
 From left: Nilesh, Saswata, me, Sahil. Photo credits: Sahil.
From left: Nilesh, Saswata, me, Sahil. Photo credits: Sahil.
 Ruchika (taking the selfie) and from left to right: Yash,
Ruchika (taking the selfie) and from left to right: Yash,  Joost and me going to Delhi. Photo credits: Ravi.
Joost and me going to Delhi. Photo credits: Ravi.
 Inspired by the fine Debian Local Groups all over the world, I ve long since wanted to start one in Cape Town. Unfortunately, there s been many obstacles over the years. Shiny distractions, an epidemic, DPL terms these are just some of the things that got in the way.
Fortunately, things are starting to gain traction, and we re well on our way to forming a bona fide local group for South Africa.
We got together at Woodstock Grill, they have both a nice meeting room, and good food and beverage, also reasonably central for most of us.
Inspired by the fine Debian Local Groups all over the world, I ve long since wanted to start one in Cape Town. Unfortunately, there s been many obstacles over the years. Shiny distractions, an epidemic, DPL terms these are just some of the things that got in the way.
Fortunately, things are starting to gain traction, and we re well on our way to forming a bona fide local group for South Africa.
We got together at Woodstock Grill, they have both a nice meeting room, and good food and beverage, also reasonably central for most of us.






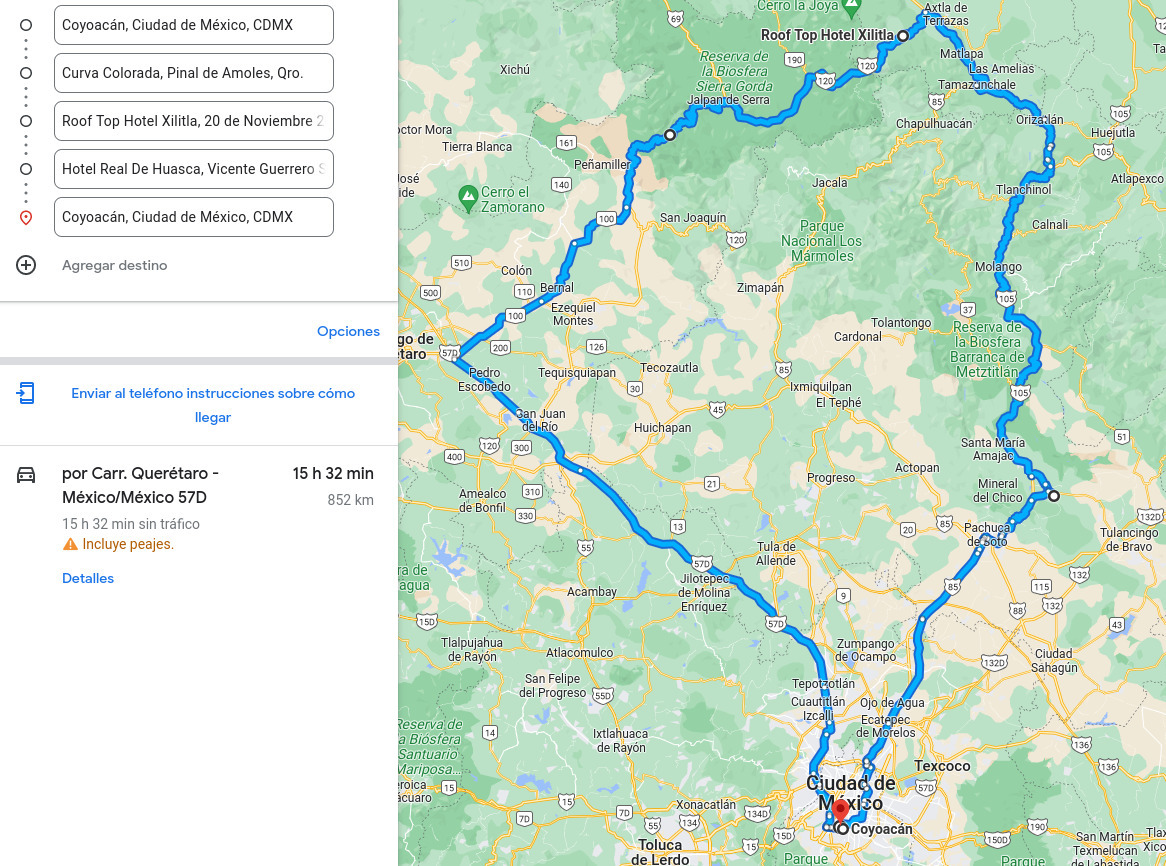
 We took a couple of days of for a family vacation / road trip through
the hills of Central Mexico. The overall trip does not look like
anything out of the ordinary
We took a couple of days of for a family vacation / road trip through
the hills of Central Mexico. The overall trip does not look like
anything out of the ordinary





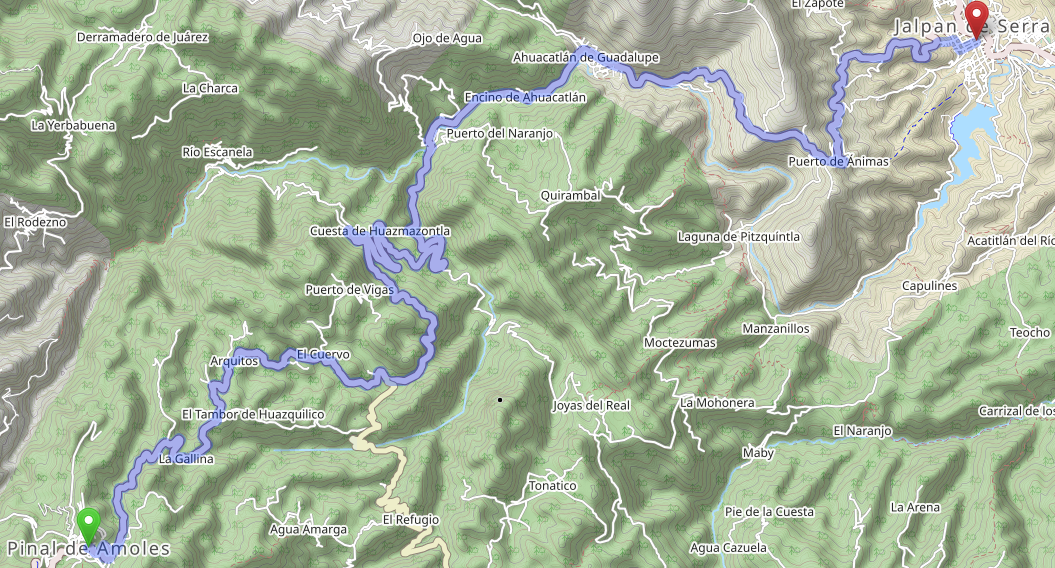


























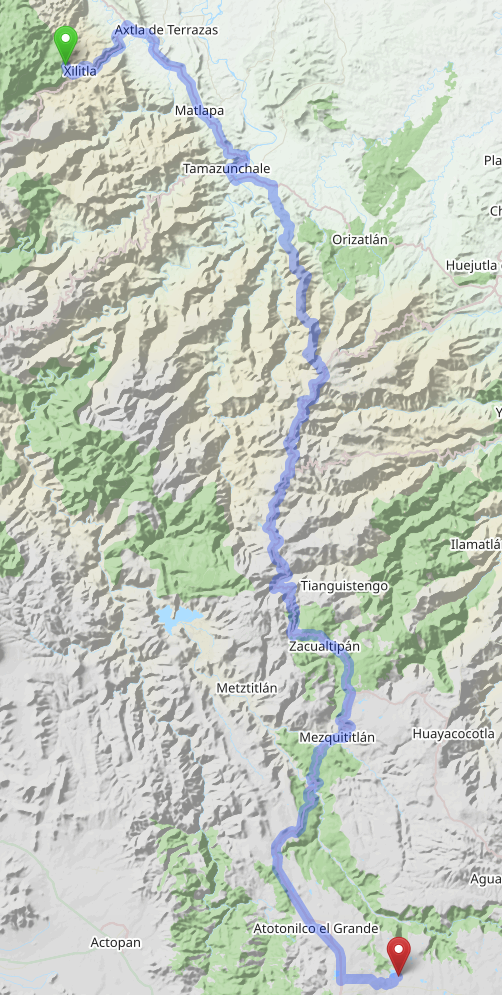

 And then up we went!
And then up we went!
 Martha was so proud when we landed! We went to Stearman Field, just a short 10-minute flight away, and parked the plane right in front of the restaurant.
Martha was so proud when we landed! We went to Stearman Field, just a short 10-minute flight away, and parked the plane right in front of the restaurant.
 We flew back, and Martha thought we should get a photo of her standing on the wing by the door. Great idea!
We flew back, and Martha thought we should get a photo of her standing on the wing by the door. Great idea!
 She was happily jabbering about the flight all the way home. She told us several times about the pin she got, watching out the window, watching all the screens in the airplane, and also that she didn t get sick at all despite some turbulence.
And, she says, Now just you and I can go flying!
Yes, that s something I m looking forward to!
She was happily jabbering about the flight all the way home. She told us several times about the pin she got, watching out the window, watching all the screens in the airplane, and also that she didn t get sick at all despite some turbulence.
And, she says, Now just you and I can go flying!
Yes, that s something I m looking forward to!
{kind=link}